Machine translation for medical chat, checkpoint #4
This series of posts is about building trustworthy machine translation for medical chat. Multilingual doctors are rare and not all patients in the US speak English. However, just using machine translation isn’t enough; physicians often have concerns with safety and trust.
My previous article was a literature review of user experience for machine translation in chat. I found that there were some promising directions in safety and trust, but the field hasn’t discovered a definitive solution yet.
In this post, I’ll describe my efforts so far to build trust by allowing users to inspect the way the words and phrases are “aligned” by the translation algorithm. In contrast with a previous prototype, I’m optimistic about it for a few reasons:
- I previously integrated dictionary definitions but found that bilingual dictionaries don’t work well for multi-word expressions. Internally, the translation algorithms support this better than dictionarys so I’m optimistic.
- I’ve also been searching for a way to teach users verb conjugation, because existing approaches don’t help with that. I’m optimistic that alignment may work.
I started out by building a prototype of the user interface. That helps me to understand whether the idea is plausible or not before spending significant time into the technical details.
Initially I sought to extract attention weights from HuggingFace machine translation models but found that it’s tougher than expected. So I decided to approximate it with a word alignment package. Keep in mind that alignment algorithms are built for training, not to explain a translation. So it’s only a rough prototype.
Let’s start with a brief demo:
Users can click words in either language and it’ll highlight the word and the aligned words in the other language. It’ll also group words into phrases based on alignment, such as grouping “help you” with “ayudarte”. Likewise “puedo” maps to “can I” though it’s a little hard to see the highlighting on “I”.
How it works
I’ll give a brief rundown:
- Translate “Hi, how can I help you today?” from English to Spanish. I used NeuML’s txtai wrapper around HuggingFace for this.
- Align the translations using SimAlign. This gives us a list of pairs of aligned words in the source and target text. Note that it needs to be tokenized, so I used spacy for tokenization.
- Find all the groups of connected words using a graph algorithm. That’s needed so that I can highlight both “ayudarte” and “you” when clicking on “help”.
- CSS & Javascript for the user interface in a Colab notebook.
If you’d like the code, it’s available here!
When it fails
Let’s review some examples where it doesn’t do as well:
In this case, “lower back” should’ve aligned to “parte baja de la espalda”. It almost worked, but I don’t want “almost” when dealing with potential medical safety issues.
“I’m sorry” should align to “Lamento” and “to hear” should align to “oír” so that’s not great. And “hear” definitely doesn’t mean “que”! The rest is pretty good though.
I also tried a basic Japanese example to get another perspective. I’d suggest to pause a moment after seeing the example and ask yourself if you could assess the quality of the translation before reading further.
The alignment should be:
- one: not translated
- coffee: コーヒー (kōhī)
- please: お願いします (onegaishimasu)
What SimAlign provides:
- one: aligned to お (o-) which is a part of onegaishimasu (please)
- coffee: not aligned
- please: aligned to 願い (negai), which is the core of the word for please
Although the SimAlign alignment component has some problems, I feel good about the user interface. When it works, it helps for showing verb conjugation and phrase translation. And it feels easier to use than many of the examples I saw in the literature review.
That said, even if the alignment problem were fixed, it’d still be an improvement to also show the dictionary definitions of each highlighted word.
Alternative: BertViz
BertViz is a project to help visualize attention weights in transformers. They even provide an example of attention in machine translation.
Here’s a recording of BertViz for a translation of the English “She sees the small elephant.” into the German “Sie sieht den kleinen Elefanten.” with the HuggingFace Helsinki-NLP/opus-mt-en-de model.
This machine translation model is a 6-layer transformer and the 8 color-coded columns are attention heads.
There’s just too much information for me here! I’d been going into this naively thinking of classic attention, where there’s only one layer and only one attention head. But I forgot that modern neural machine translation isn’t nearly as simple. There might be good alignment information in certain layers or heads, but I don’t know of a systematic way to find the right layers or heads (yet).
I also tried to get it to work with the HuggingFace MarianMTModel models but it didn’t work. Those models use a different setup that isn’t compatible with BertViz. So I’ll need to dive more into HuggingFace and PyTorch to do it myself.
When in doubt, lit review!
At this point, I wasn’t sure if what I wanted was possible but also it seems like the sort of thing that a researcher might publish. So I did some searching and read a few of the results so far.
Koehn, P., & Knowles, R. (2017). Six Challenges for Neural Machine Translation. 28-39. https://doi.org/10.48550/arxiv.1706.03872
On page 1 we have a key quote:
The attention model for [neural machine translation] does not always fulfill the role of a word alignment model, but may in fact dramatically diverge.
In most language pairs, they found that attention weights were similar to word alignment. However, in one language pair, attention weights were all offset by 1 word and they didn’t find any good explanation.
Munz, T., Ath, D. V., Kuznecov, P., Thang Vu, N., & Weiskopf, D. (2021). Visual-Interactive Neural Machine Translation. Graphics Interface 2021 Conference Second Cycle. https://github.com/MunzT/NMTVis
This paper has some wonderful graphics of what I’d like to build!

It looks so nice! Though it’s a little tough to tell from the lines alone if verarbeiten only means process or if it means easy to process. Here’s what it looks like if I run it through my demo and inspect those words:
So verarbeiten probably just means process. To be fair, if I could click their user interface in their paper I would likely find the same.
Here’s another example of showing the full alignment:
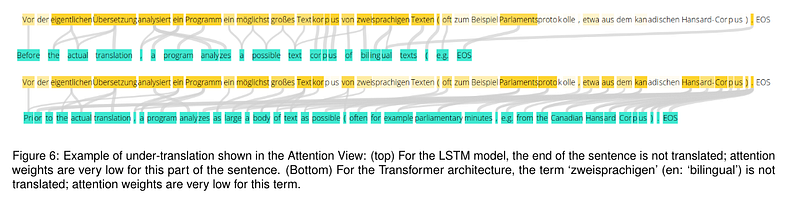
There’s a big section in the top example that doesn’t line up to anything. It wasn’t translated at all! So even zoomed out this type of visual can help to detect certain translation errors without knowing the target language.
Unfortunately, most of their examples are with an LSTM and a simple attention mechanism. They tried working with Transformer architectures in some examples but just averaged attention heads. In the picture above, it’s connecting words to too many others, not just the aligned one.
This paper gave me a great example of what I’d like to build but didn’t show how to use Transformer attention weights.
I also want to note that I’ve only discussed a piece of the paper – it’s a larger system to help professional translators and I enjoyed reading it.
Bibal, A., Cardon, R., Alfter, D., Wilkens, R., Wang, X., François, T., & Watrin, P. (2022). Is Attention Explanation? An Introduction to the Debate. ACL, 1, 3889-3900. https://doi.org/10.18653/V1/2022.ACL-LONG.269
This is another great read!
Explanations can be faithful (how close the explanation is to the inner workings of the model) or plausible (does the user consider the explanation of the model plausible?)
This early note helps me describe what went wrong with SimAlign: The alignments were sometimes plausible but not faithful.
I found the section “Is Attention Explanation on Different Tasks?” also very relevant. Although attention in general may not be good for explainability, there have been more successes in natural language processing.
This quote leaves me optimistic about attention for explanation of machine translation:
… however does not hold true for self-attention networks nor for tasks depending on an additional text sequence, as for example in neural machine translation or natural language inference (pair-wise tasks and text generation tasks). In such cases, altering learned attention weights significantly degrades performance and attention appears to be an explanation of the model and to correlate with feature importance measures.
They also have citations that investigate how to deal with multi-head, multi-layer attention!
So where does that leave us?
I feel good about the simplicity of the user interface, and I’m sure it could be a good interface with more work. (Though of course I should test that!)
SimAlign isn’t sufficient for alignment but I think it’ll be possible to get more faithful alignments by extracting them from cross-attention in the txtai/HuggingFace machine translation models. But to do it, I need to first learn 1) more about PyTorch 2) how to flatten multi layer multi head attention.
The one major downside is that this means I won’t be able to use Google/Microsoft/Amazon Translate APIs if I’m showing alignment this way. That’s a bummer because the Microsoft APIs look nice for building a domain-adapted model.
So that’s where I’m at in the project! Sorry I didn’t get to the point of a satisfying conclusion yet. The next step is to learn more about PyTorch and HuggingFace.
Also if you spot any errors or have ideas, let me know!
Appendix/notes
- I made a mistake in the first version of this post with Japanese, because the tokenization is a little tricky. Originally I used spacy’s tokenizer but the alignment was poor. Then I read up about SimAlign and the multilingual BERT model under the hood, finding a note that they split Japanese text at the character level not word level. So I redid it with character tokenization which was a slightly improvement.
- SimAlign has three different alignment algorithms. I tried all three and settled with itermax. The different approaches seem generally similar in their publication so that probably doesn’t invalidate my results but if you know more about them let me know.